
 医療・創薬・医療機器
医療・創薬・医療機器
 ライフサイエンス
ライフサイエンス
 環境
環境
 ナノテクノロジー・材料
ナノテクノロジー・材料
 エネルギー
エネルギー
 ものづくり・機械
ものづくり・機械
 社会基盤・安全
社会基盤・安全
 フロンティア・宇宙
フロンティア・宇宙
 人文・社会
人文・社会

 ビッグデータの意味解析を可能にする自然言語処理技術
ビッグデータの意味解析を可能にする自然言語処理技術
更新:2020/06/16


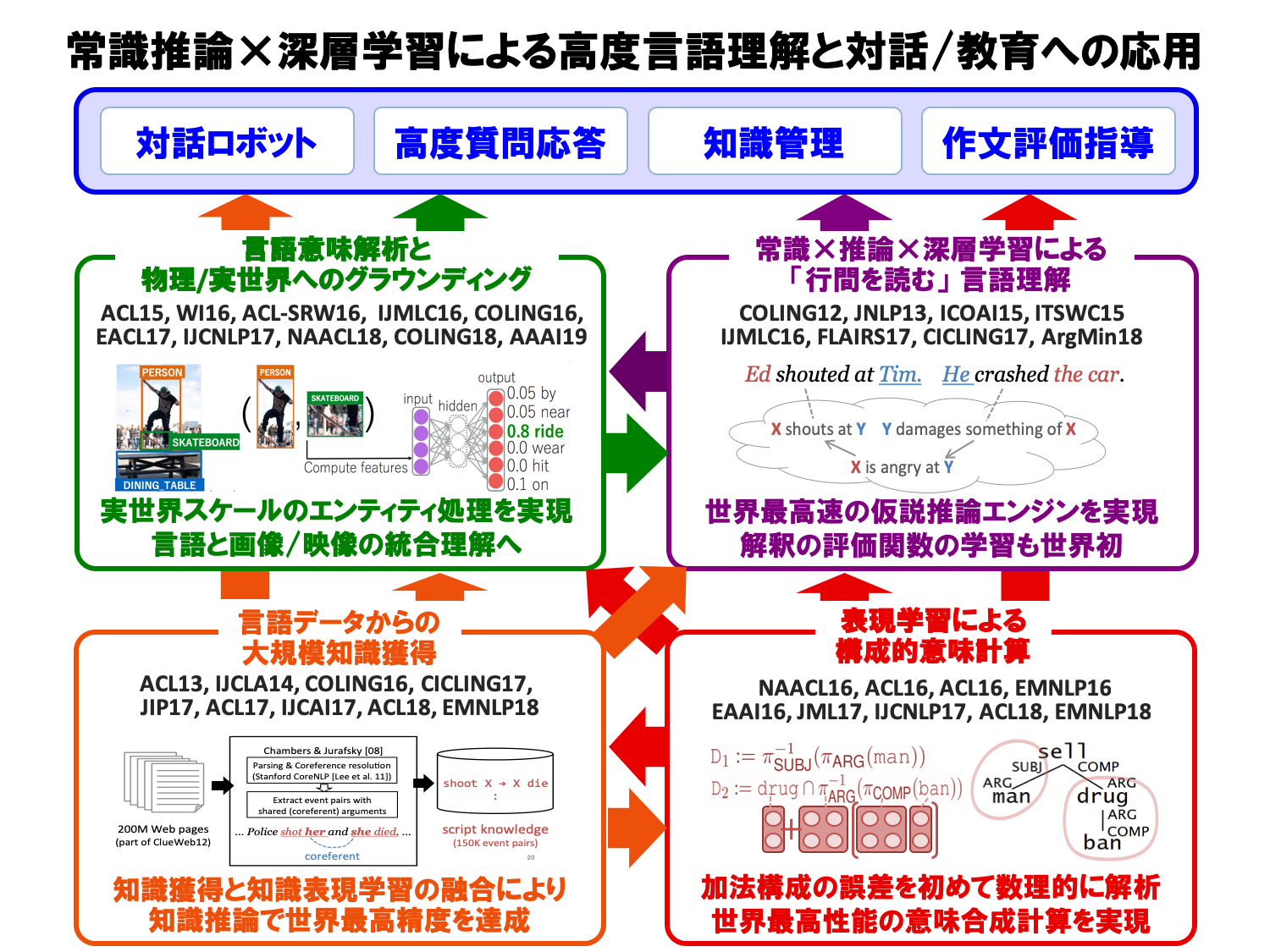
- 特徴・独自性
-
膨大な言語データを意味的に解析し必要な情報・知識を抽出する技術、抽出した情報・知識を分類・比較・要約する技術、それらを可能にする世界最速の仮説推論技術など、先進的な自然言語処理技術を研究開発しています。また、これら基盤技術をウェブやソーシャルメディアなどのビッグデータに適用し、大規模な情報・知識マイニングや信頼性の検証支援、耐災害情報処理などに応用する実践的研究も展開しています。
- 実用化イメージ
-
言語意味解析に基づく高度なテキストマイニングによる市場動向調査や技術動向調査、隠れたニーズやリスクの発見、社内文書の構造化・組織化による知識管理支援、対話システムなど、多様な分野・業種との連携が可能です。
- キーワード
研究者
言語AI研究センター
乾 健太郎 教授
修士(工学)(東京工業大学)/博士(工学)(東京工業大学)
Kentaro Inui, Professor
