
 医療・創薬・医療機器
医療・創薬・医療機器
 ライフサイエンス
ライフサイエンス
 環境
環境
 ナノテクノロジー・材料
ナノテクノロジー・材料
 エネルギー
エネルギー
 ものづくり・機械
ものづくり・機械
 社会基盤・安全
社会基盤・安全
 フロンティア・宇宙
フロンティア・宇宙
 人文・社会
人文・社会

 大規模言語モデルを支える自然言語処理技術
大規模言語モデルを支える自然言語処理技術
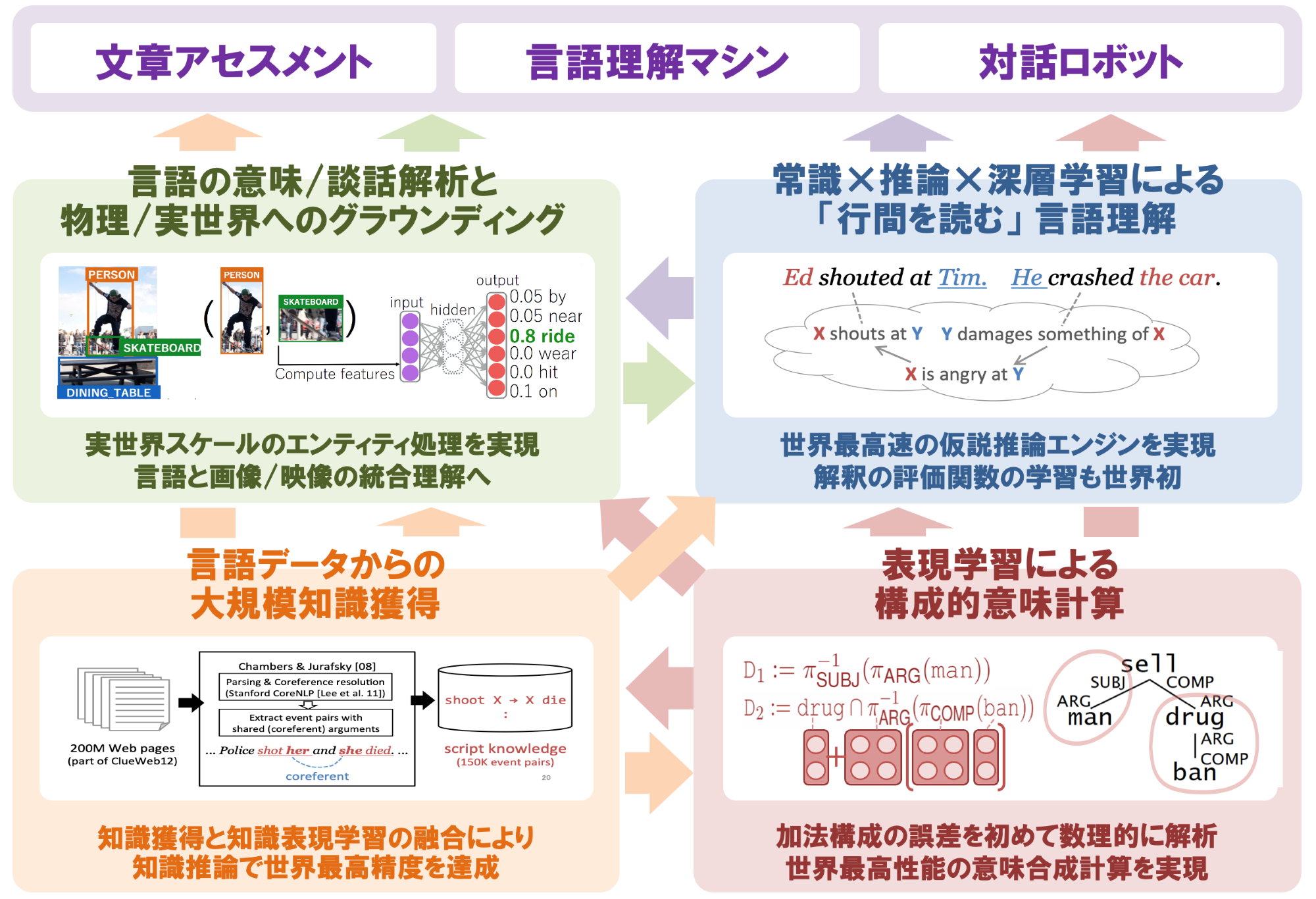
- 概要
- 従来技術との比較
- 特徴・独自性
-
私たちは、言語モデルの推論過程や数量・記号の処理メカニズムを解明し、自然言語処理技術のさらなる発展を目指しています。統計的な機械学習モデルが数値や記号をどのように処理し、学習データから得た知識を推論時にどのように活用しているのかを観察・分析することで、高信頼性かつ解釈可能なAIシステムの開発を推進します。また、これらの基盤技術を応用し、実世界で運用可能な対話システムの開発や、教育支援、耐災害情報処理、異常検知といった実践的な研究にも取り組んでいます。さらに、法律・医療・化学・脳科学・コンピュータビジョンなど、多様な学際領域と連携し、自然言語処理技術の新たな応用可能性を探求しています。
- 実用化イメージ
-
本技術は、高信頼な知識検索・要約により、論文・技術レポート・公的文書などの情報整理や要約を通じて、研究開発や政策立案を支援する可能性があります。また、専門分野向け言語モデルを活用し、医療・法律・科学技術分野での文書解析・翻訳・要約の精度向上が期待されます。さらに、学習支援システムとして、記述式答案の自動採点や個別最適化フィードバックを活用することで、教育の質向上に寄与することが考えられます。次世代対話システムにおいても、カスタマーサポートやヘルスケア相談などで、より自然な対話の実現が見込まれます。加えて、言語モデルによる推論過程の可視化を通じ、AI活用の透明性・公正性の向上が期待されます。耐災害情報処理・異常検知に関しても、災害時の情報整理やフェイクニュースのフィルタリングによる迅速な情報提供の支援が想定されます。
- キーワード
研究者
大学院情報科学研究科
システム情報科学専攻
知能情報科学講座(自然言語処理学分野)
坂口 慶祐 教授
Ph.D.(Johns Hopkins University)/修士(工学)(奈良先端科学技術大学院大学)/M.A.(University of Essex)
Keisuke Sakaguchi, Professor
